

Sanger和 NGS的可视化(宏基因组、RNA-seq),序列拼接,查找SNP,基因组注释,DNA序列及蛋白质序列的统计、预测等,查找Motif、ORF,比对序列与构建进化树等功能。
1、自动基因组注释
根据公共或本地数据库中的现有模式和注释自动注释新基因组,包括根据这些模式将 ORF 注释为假设基因,并针对 NCBI 进行查询。
2、实时序列预测
对DNA和蛋白质序列进行翻译,预测分子量、等电点、疏水性、跨模结构域等。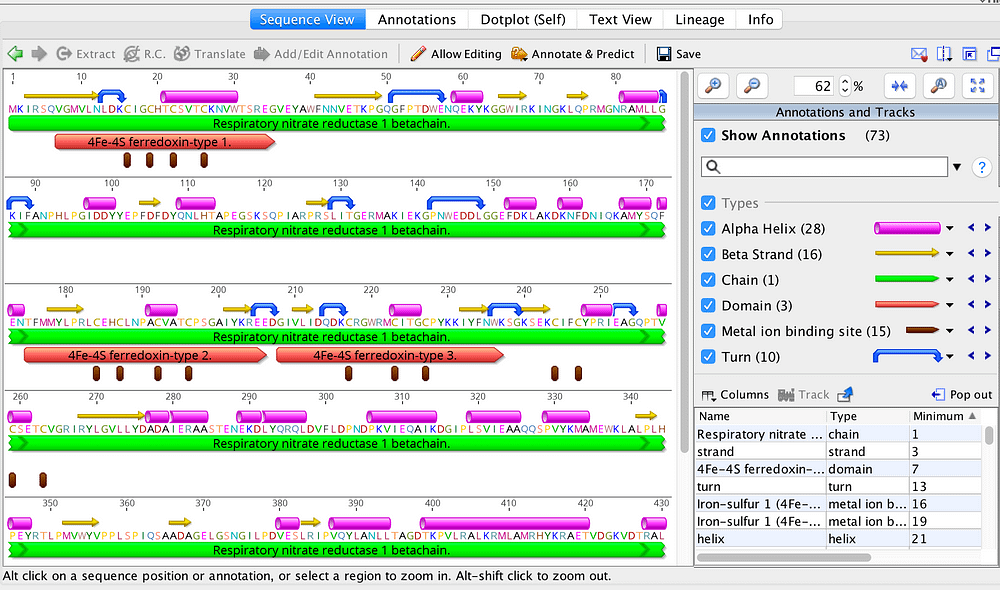
3、NGS可视化
只需单击一下,即可获得您拥有的下一代测序数据所需的可视化效果。注释的基因组,循环基因组,映射的读取,重叠群都显示在我们高度可定制的序列视图中。选择要显示的其他批注的配色方案、图形和轨迹,然后使用动态批注搜索和位置跳转来查找所需内容。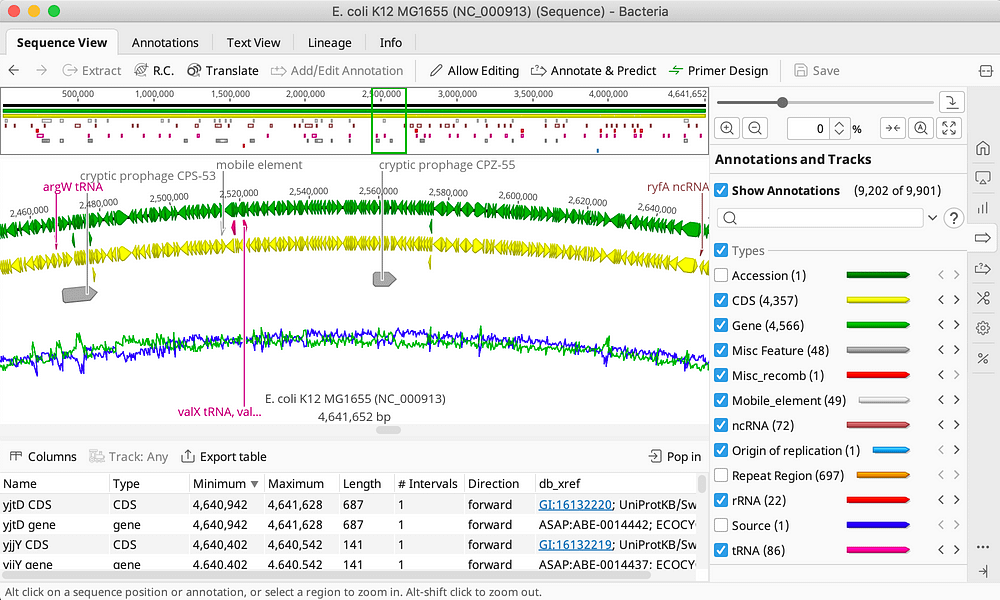
4、转录组数据分析
从映射的读数中计算表达水平,然后在样品之间进行成对比较,以鉴定差异表达的基因。在统计编程语言R方面没有任何专业知识的情况下,使用行业标准的DESeq2包来比较两个条件之间的表达式,每个条件都有重复样本。
切换到 PCA 图选项卡以使用主成分分析检查数据的质量,然后切换到交互式火山图以发现感兴趣的基因。在火山图中选择一个基因后,您可以在序列视图中直接跳转到该基因,其中所有基因都具有基于差异表达的热图着色。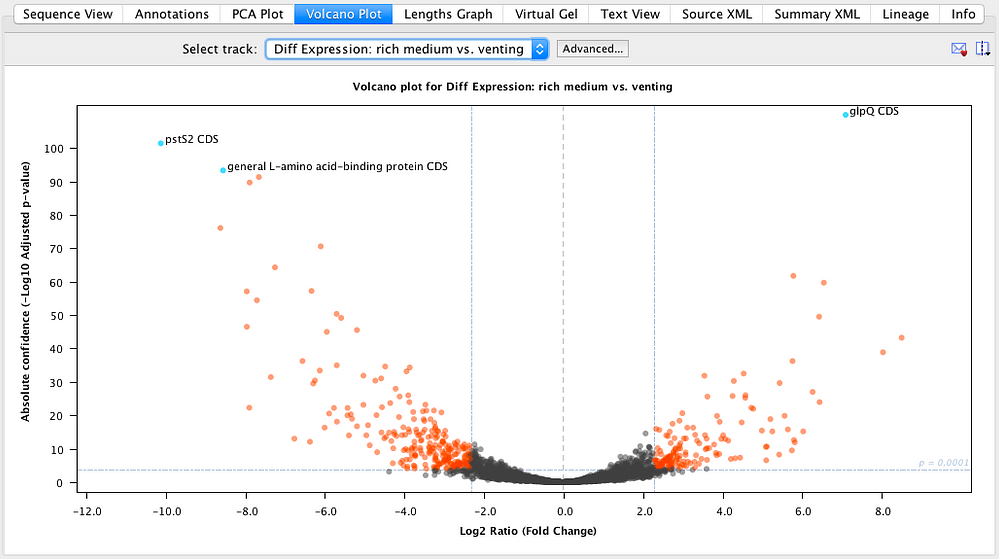
5、序列拼接
可以处理来自任何类型的测序机器的数据,读取任何长度的读数,包括配对读取和来自不同测序机器的混合读取。它特别适用于具有产生圆形重叠群的独特能力的微生物组件。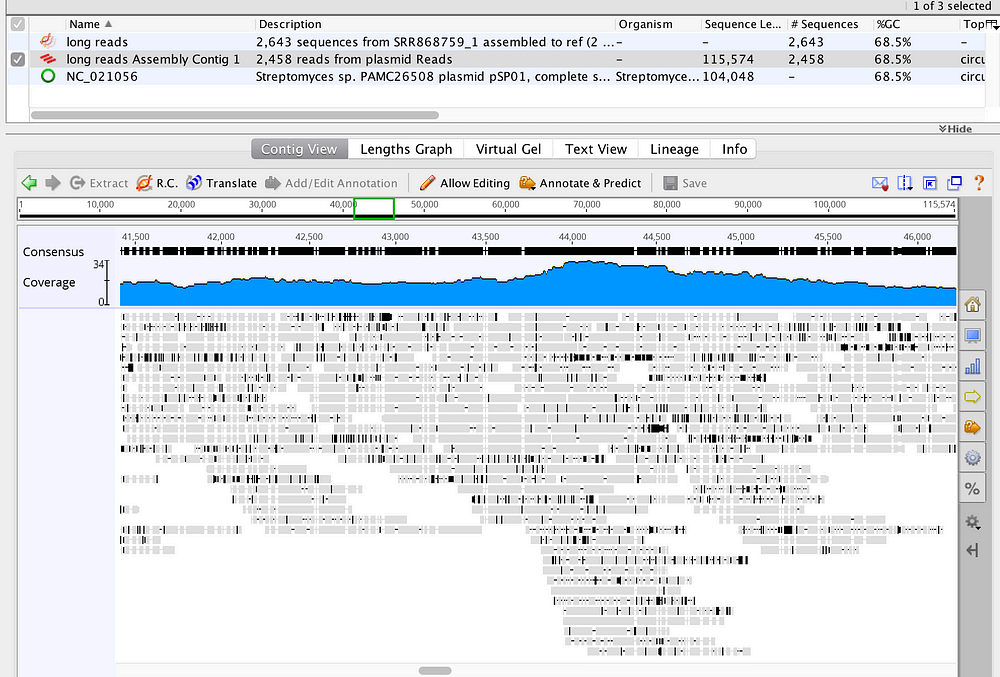
6、序列比对
使用如Clustal Omega、MUSCLE、MAFFT等多种比对方式将序列进行对齐分析。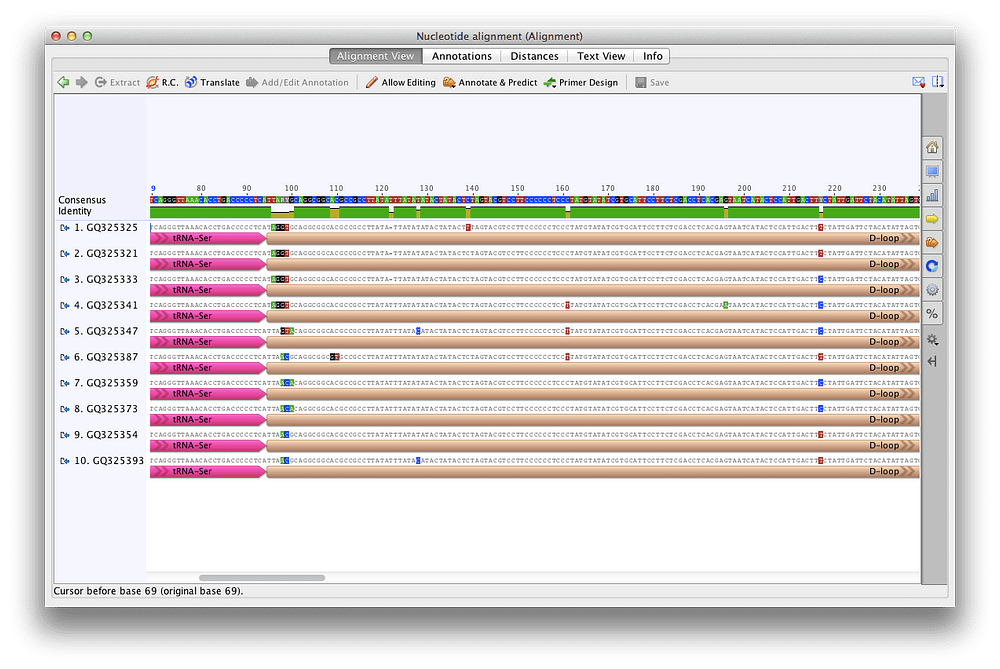
7、系统发育进化树构建
使用多种算法对目的序列构建进化树,如MrBayes、Neighbor Joining、UPGMA、PhyML。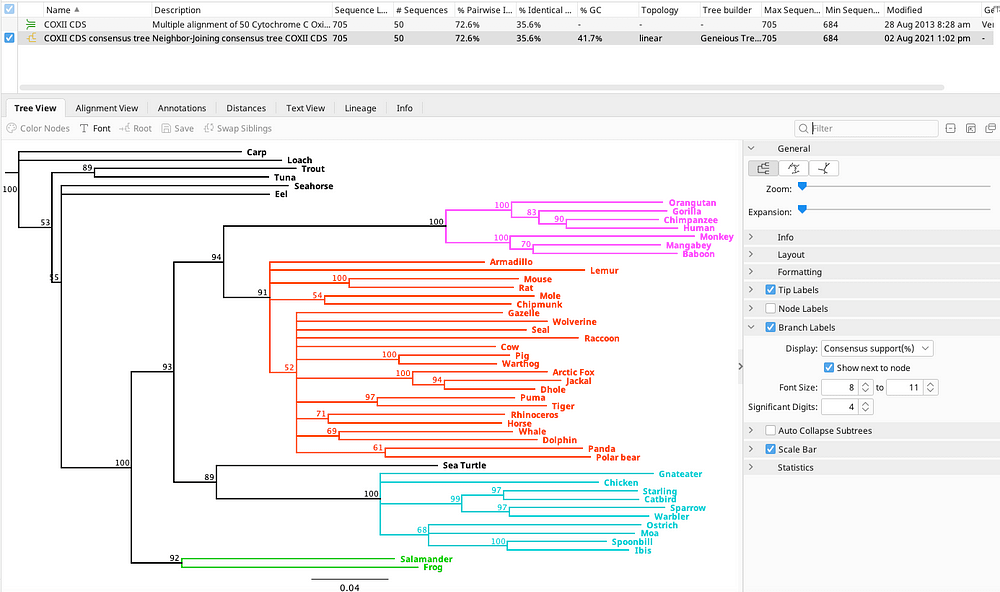



 苏公网安备 32059002002276号
苏公网安备 32059002002276号